소프트웨어 스크린 샷:
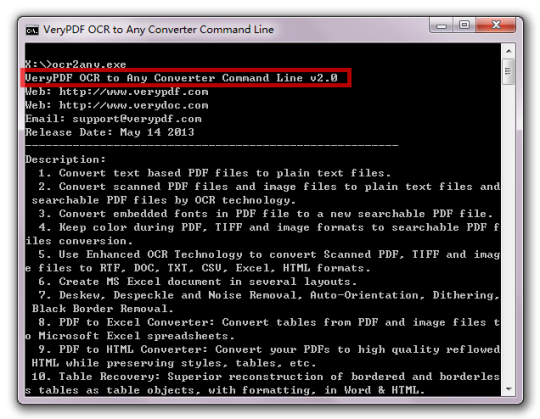
PDF로 OCR 변환기 명령 줄 스캔 한 PDF 파일에서 문자를 인식 및 광학 문자 인식 기술을 텍스트 문서 텍스트에 이미지에서 텍스트를 추출 할 수있는 텍스트입니다. 명령 줄 응용 프로그램에서 스크립트를 사용하여 일괄 처리를 구현하기위한 편리하고, 또한 효과적인 옵션을 제어 설명서 편의를 제공합니다. 광학 문자 인식 (OCR)은 인쇄 또는 전자 문자 기반 파일에 텍스트를 작성 켤 수있는 시각적 인식 과정입니다. PDF 문서로 스캔 변환되는 문서는 문자 인식 소프트웨어는 PDF 각 문자 화상을 해석하고 그것을 그러한 텍스트와 같은 편집 가능한 형식으로 입력 할 수있는 전자 문자 기반 파일을 할당 할 수있는 기초를 제공한다 또는 Word 문서.
스캔 한 PDF에서
많은 문서가 이미지 형식으로 실제로 스캔 한 PDF 파일에 저장됩니다. 이 문서를 보관 또는 인덱싱 쉽지 않다. PDF로 OCR 변환 (CMD)는 스캔 한 PDF로 단어와 텍스트를 인식하기위한 좋은 도우미입니다 텍스트.
텍스트 문서에 이미지에서 b.Extract 텍스트
스캐너 또는 사진에서 만든 문서에 복사하거나 텍스트를 편집하는 것은 항상 시간이 소요됩니다. 이 응용 프로그램은 이미지에 텍스트 메시지를 처리하기 위해 많은 시간을 절약 할 수 OCR 기술을 가진 이미지에서 텍스트를 인식 할 수 있습니다.
c.Easy 명령 줄 작업 및 배치 처리
이 스크립트 배치 프로세스를 구현하기위한 편리 명령 행 애플리케이션이다. 명령 줄 응용 프로그램은 또한 효과적인 옵션을 제어 설명서 편의를 제공합니다. 명령과 함께, 배치 및 수동 제어는 모든 쉽다.
PDF의 특징은 OCR 변환기 명령 줄을 텍스트 :
1.Convert는 편집 가능한 텍스트 파일을 PDF 파일을 검사했습니다.
이러한 TIFF, BMP, PNG, JPG, PCX, 및 TGA 등의 이미지에서 2.Recognize 문자.
3.Convert는 (정보 URL에서 다운로드 언어 패키지) 소스 파일의 페이지를 지정했습니다.
4.No 타사 PDF 리더 응용 프로그램이 필요합니다.
5.Support 열 개 이상의 언어.
PDF 원본 파일의 원래의 레이아웃을 유지 6.Able.
읽기 순서 레이아웃과 텍스트로 PDF를 변환 7.Able.
8.Support 일괄 처리에 유용합니다 명령 줄 작업.
제한 사항 :
(100) 사용 시험

댓글을 찾을 수 없습니다