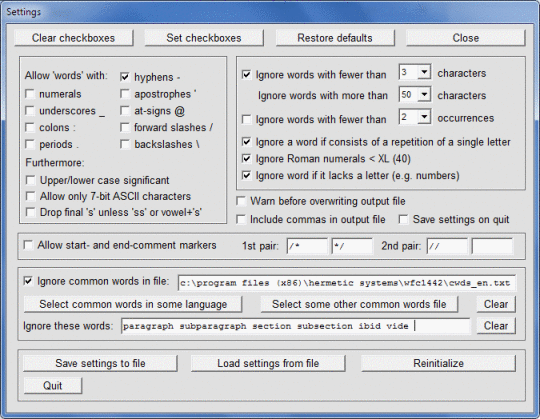
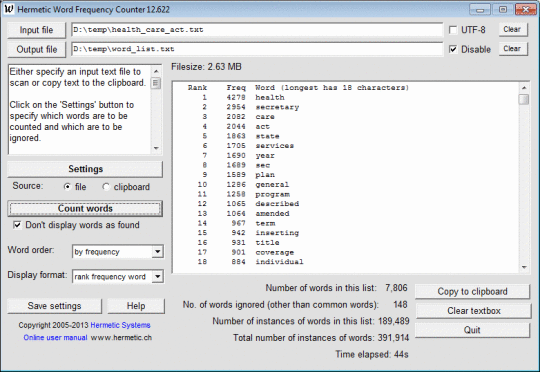
이 소프트웨어는 ANSI 또는 UTF-8을 통해 인코딩 된 텍스트로 MS Word docx 파일이나 텍스트 파일 (HTML 및 XML 파일 포함)을 스캔하고 다른 단어의 빈도를 계산합니다. 발견되어 표시되는 단어는 사전 순 또는 빈도 순으로 정렬 할 수 있습니다. 단어로 나타날 수있는 문자를 지정할 수 있으므로 숫자, 하이픈, 아포스트로피, 밑줄 또는 콜론이 포함 된 단어를 허용하거나 금지하거나, 짧거나 자주 발생하지 않는 단어를 무시하고 대 / 소문자를 다음과 같이 처리하도록 프로그램에 지시 할 수 있습니다. 중요한지 아닌지와 특정 파일에 포함 된 단어 (예 : 'this'와 같은 일반적인 단어)를 무시합니다. 이 소프트웨어는 영어 이외의 언어, 특히 프랑스어, 독일어, 이탈리아어 및 스페인어 텍스트로 된 텍스트와 함께 사용될 수 있습니다. 텍스트의 언어가 자동으로 감지되고 무시할 단어가있는 해당 '공통 단어'파일이 선택적으로로드됩니다. 결과를 출력 파일에 기록한 다음 추가 처리를 위해 Excel로 읽을 수 있습니다.
이 릴리스의 새로운 기능은 다음과 같습니다.
버전 19.36 : / p>
버전 19.26의 새로운 기능 :
설치 개선.
XML 파일 처리 개선
버전 16.52의 새로운 기능 :
버전 16.52에는 지정되지 않은 업데이트, 향상된 기능 또는 버그 수정이 포함될 수 있습니다.
버전 16.42의 새로운 기능 :
버전 16.42에는 지정되지 않은 업데이트, 개선 사항 또는 버그 수정이 포함될 수 있습니다.
버전 16.22의 새로운 기능 :
버전 16.22에는 지정되지 않은 업데이트, 향상된 기능 또는 버그 수정이 포함될 수 있습니다.
버전 15.52의 새로운 기능 :
UTF-8로 인코딩 된 텍스트 파일의 인식에서 버전 15.52가 버그 수정.
버전 14.42의 새로운 기능 :
영어 / 중국어 텍스트가 혼합 된 파일에 대한 지원이 추가되었습니다.
제한 사항 :
30 일 평가판, 제한된 기능
댓글을 찾을 수 없습니다