소프트웨어 스크린 샷:
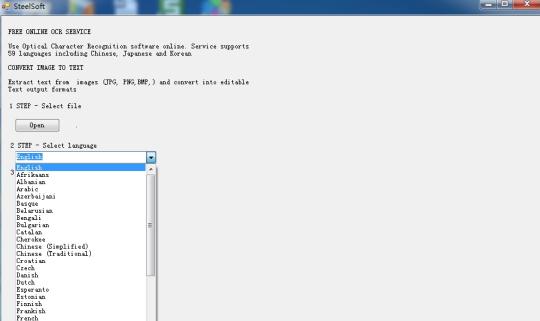
클라우드 기술 기반 Tesseract OCR 엔진을 사용하여 이미지의 텍스트를 인식한다.
온라인 광학 문자 인식 소프트웨어를 사용합니다. 서비스 일본어와 중국어, 한국어를 포함한 59 개 언어를 지원합니다. 이미지 (JPG, PNG, BMP, TIF)에서 텍스트를 추출 및 편집 가능한 텍스트 출력 형식으로 변환합니다.
이것은 클라우드 기술, 매우 유명 OCR 엔진 (Tesseract OCR 엔진)에 기초하므로이 크기 KB의 수백이지만,이 화상으로부터, (59)의 언어로 텍스트를 추출 할 수있다.
불가리아어, 카탈루냐어, 체코 어, 덴마크어, 네덜란드어, 영어, 핀란드어, 프랑스어, 독일어, 그리스어, 노르웨이어, 인도네시아어, 이탈리아어, 라트비아어, 리투아니아어, 헝가리어, 폴란드어, 포르투갈어, 루마니아어, 러시아어, 세르비아어, 슬로바키아어, 슬로베니아어 : 그것은 더 많은 언어를 지원합니다 , 스페인어, 스웨덴어, 타갈로그어, 터키어, 우크라이나어, 베트남어 등
이 릴리스의 새로운 기능 :..
버전 5.0 (UE)의 개선 사항이 포함되어

댓글을 찾을 수 없습니다