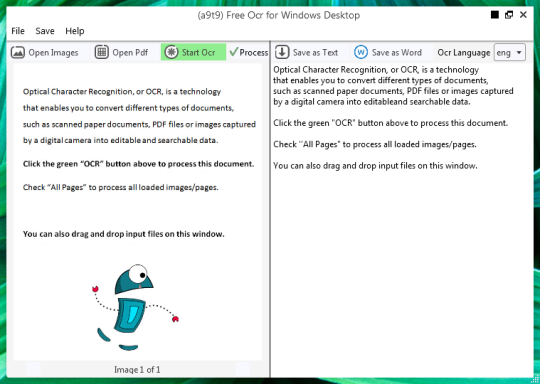
무료 OCR 소프트웨어는 이미지 파일 및 PDF 항목에서 텍스트를 추출합니다. 테세 랙트 OCR 엔진 용 그래픽 사용자 인터페이스 (GUI).
이 응용 프로그램은 오픈 소스와 100 % 애드웨어 및 스파이웨어 무료로 자유롭게 사용할 수, 더 중요한 것은, 설치하고 간단하다.
당신은 이미지 나 PDF 파일을 열 수 있습니다. 소스 파일의 콘텐츠는 왼쪽 창에 표시 될 것이다. 당신은 여러 페이지의 문서를 열 경우 하나 이상의 페이지로 문서, 또는 그들 사이를 전환 하단에있는 화살표를 사용하는 경우,
당신은 녹색 OCR 버튼을 클릭하여 OCR을 시작하고, 두 번째 오른쪽 창에 결과를 볼 수 있습니다. 출력 텍스트가 텍스트 파일이나 워드 문서로 저장할 수 있습니다.
불행하게도 변환 품질은 그렇게 크지 않다. 장면 뒤에 그것은 테 저렉 오픈 소스 OCR 엔진을 사용합니다. 품질은 언어와 언어 변화 -. 그것은 당신의 요구에 충분하다면 그렇게 가서 테스트
소프트웨어 개발자 및 괴짜 : 윈도우 데스크탑 도구 무료 OCR 본질적 테세 랙트 OCR 엔진에 대한 그래픽 사용자 인터페이스 프런트 엔드 (GUI)이다. 전체 소스 코드 (GPL 라이센스)을 사용할 수 있습니다.
소프트웨어의 OCR 엔진은 다음과 OCR 언어를 지원 : 영어, 프랑스어 이탈리아어, 독일어, 포르투갈어, 네덜란드어 브라질, 스페인어. 이 헝가리 불가리아 아랍어, 카탈로니아 어, 중국어 (간체 및 번체), 크로아티아어, 체코 어, 덴마크어, 네덜란드어, 영어, 독일어 (표준 및 Fraktur 스크립트), 그리스어, 핀란드어, 프랑스어, 히브리어, 힌디어를 인식 할 수있는 버전 3을 시작으로, 인도네시아어, 이탈리아어, 일본어, 한국어, 라트비아어, 리투아니아어, 노르웨이어, 폴란드어, 포르투갈어, 루마니아어, 러시아어, 세르비아어, 슬로바키아어 (표준 및 Fraktur 스크립트), 슬로베니아어, 스페인어, 스웨덴어, 타갈로그어, 타밀어, 태국어, 터키어, 우크라이나어, 베트남어.
댓글을 찾을 수 없습니다